
 Artetsu Saria 2005
Artetsu Saria 2005
Arbaso Elkarteak Eusko Ikaskuntzari 2005eko Artetsu sarietako bat eman dio Euskonewseko Artisautza atalarengatik
 Buber Saria 2003
Buber Saria 2003
On line komunikabide onenari Buber Saria 2003. Euskonews y Media
 Argia Saria 1999
Argia Saria 1999
Astekari elektronikoari Merezimenduzko Saria

Darrell CONKLIN, Departamento de Ciencias de la Computación e Inteligencia Artificial de EHU-UPV y Fundación Ikerbasque
Los años recientes han visto un interés renovado en el análisis de la música folclórica, debido al interés en el patrimonio cultural y a los avances en informática musical. La capacidad de analizar diferentes características de canciones, partiendo de su contenido musical, como son topónimo, tipo de danza, familia de canción, tonalidad y función social, nos aporta métodos importantes para gestionar y entender los grandes cancioneros.
Este artículo describirá un proyecto que es una colaboración entre tres entidades en el País Vasco: la Fundación Euskomedia, la Fundación Eresbil y el investigador principal, un Ikerbasque Research Profesor del Departamento de Ciencias de la Computación e Inteligencia Artificial de la Universidad del País Vasco.
El proyecto tiene como objetivo el análisis de las características musicales de cancioneros populares vascos mediante un descubrimiento automático de patrones musicales. Este proyecto nos permitirá abordar una nueva vía de estudio y análisis de los elementos esenciales de la composición musical de música vasca, que nos facilite el estudio de la evolución y el origen de nuestras melodías vascas y, a medio plazo, nos permita realizar clasificaciones automáticas de las mismas.
El interés de Euskomedia Fundazioa en el proyecto de investigación está basado en el proyecto “Euskal Kantutegia”. La fundación Eresbil ha participado en el proceso de edición del Cancionero Vasco del P. Donostia (˜1900 canciones), así como en la transcripción del Cancionero Popular Vasco de R.M. Azkue (˜1200 canciones). Actúa como coordinador de contenidos del proyecto Kantutegia de Eusko Ikaskuntza, proyecto de vaciado de los cancioneros tradicionales vascos en una base de datos para consulta y difusión.
Los cancioneros mencionados tienen dos tipos de datos asociados con cada canción: datos musicales (en formato MIDI) que codifican la melodía; y los metadatos, que representan las características globales de la canción. Entre ellos el topónimo (lugar de recogida de la canción) y el género de canción (indicado por musicólogos) son los más importantes para nuestro estudio. En la catalogación del Cancionero Vasco se utilizan un total de 24 géneros distintos, además de topónimos organizados en niveles de territorio, municipio y núcleo. Como indicamos más adelante, cada topónimo o género distinto se vincula con una clase de una ontología, y utilizaremos algoritmos de minería de datos para reconocer asociaciones o reglas entre el contenido musical y las clases de las canciones.
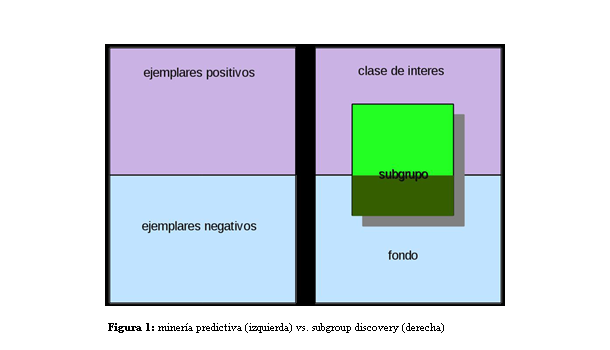
La minería de datos (a partir de ahora “data mining”) consiste en técnicas para extracción de conocimiento en grandes bases de datos. En la actualidad, el data mining se utiliza en todos los campos de estudio de las ciencias naturales y sociales, incluso en las humanidades. La mayoría de los éxitos en data mining han sido utilizando modelos predictivos, en que los objetos (canciones, imágenes, etc.) son etiquetados como positivo o negativo, intentando aprender reglas automáticamente para separar las dos clases y para prever con precisión la clase de cualquier nuevo objeto que nos encontremos. En la Figura 1 (izquierda) se muestra un conjunto de objetos dividido en ejemplares positivos y negativos.
En el Cancionero Vasco hay 341 canciones sin indicación de género y más de 200 sin indicación de topónimo. Podemos usar métodos predictivos para prever una posible clase para cada uno de ellos, y también para nuevas canciones recogidas por musicólogos en el futuro.
En los últimos años, ha surgido un paradigma nuevo y potente, llamado subgroup discovery (SD) (Kralj Novak et al. 2009)1, que no tiene el objetivo de aprender reglas para describir todos los objetos positivos, sino sólo una subconjunto (subgrupo) entre ellos. En la Figura 1 (derecha), podemos ver en color morado una clase de nuestro interés (que puede ser cualquiera de nuestros topónimos o géneros) y en color azul el fondo (todas las otras clases). En oposición a métodos predictivos, SD necesita realizar dos tareas: identificar subgrupos interesantes y, entonces (de hecho, en paralelo), describirlos por medio de un patrón comprensible. En contraste con métodos predictivos, los patrones aprendidos mediante SD no se aplican a todos ejemplares, sino únicamente a aquellos que forman parte del subgrupo identificado (regiones color verde).
Para extender el SD hacia la música, Conklin (2010)2 describió la idea de usar patrones secuenciales para descubrir subgrupos. Un patrón secuencial en música es una secuencia de características de notas, por ejemplo, [+2,+1] es un secuencia de intervalos entre notas en una melodía que tiene instancias como (por ejemplo) los secuencias de notas [C,D,Ef] o [D,E,F].
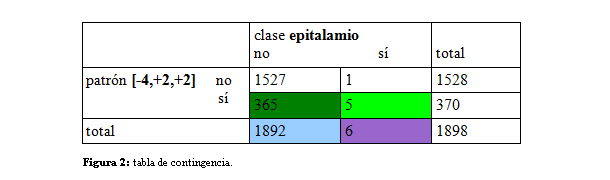
Para descubrir patrones usaremos el método llamado MGDP (maximally general distinctive pattern) de Conklin (2010) que descubre asociaciones entre patrones y clases. Los dos conceptos destacables del método son distinción y generalidad. Es importante ordenar los resultados principalmente por medidas de asociación estadística. Por ejemplo, en la Figura 2 tenemos una tabla de contingencia de un patrón interválico [-4,+2,+2] que describe un subgrupo de canciones de género epitalamios. El patrón aparece en 5/6=83% (región verde claro entre región morada) de canciones de genero epitalamios, pero solo en 365/1892=19% (región verde oscuro entre región azul) de canciones de otros géneros. Podemos decir que este patrón es distintivo de las canciones de género epitalamios, porque su frecuencia relativa en esta clase de interés es más alta que en el fondo.
También el concepto de generalidad o subsumición es muy importante para estructurar el espacio de búsqueda y presentación de patrones. Digamos que un patrón está subsumido por otro si todas las canciones que contienen el patrón, también contendrán el otro (por ejemplo, el patrón [+2] subsume el patrón [-4,+2,+2]). El algoritmo MGDP descubre un conjunto de patrones que son ambos distintivos y entre ellos más general (no subsumidos por otros patrones distintivos). El algoritmo fue aplicada con éxito a música folclórica de Creta (Conklin y Anagnostopoulou 2011)3.
Canciones en el subgrupo de epitalamio:
http://www.euskomedia.org/cancionero/001941
http://www.euskomedia.org/cancionero/002092
http://www.euskomedia.org/cancionero/001816
http://www.euskomedia.org/cancionero/002410
http://www.euskomedia.org/cancionero/001616
Una ontología es una estructuración de clases en forma jerárquica. En este proyecto aprovecharemos las jerarquías naturales de topónimos (territorios, municipios, núcleos) que nos proporcionan clases de tamaño diferente que engloban las canciones.
Las ontologías son importantes para crear clases más amplias. Hemos encontrado que los mejores métodos predictivos de clasificación de música folclórica (Hillewaere et al. 2009)4 tienen una baja precisión en el Cancionero Vasco, porque los cancioneros tienen muchas clases con muy pocos ejemplares (p.e., la clase ya mencionada epitalamio tiene solo seis ejemplares), un escenario difícil bien conocido en data mining predictivo. También sabemos que los géneros son fluidos, es decir, una canción puede tener más de una función o género, pero los musicólogos únicamente han anotado uno de ellos. El crear ontologías con clases más generales permitirá descubrir patrones más frecuentes en los cancioneros.
Todas las ontologías en el proyecto serán codificadas en OWL (Web Ontology Language). OWL es un formalismo lógico muy poderoso y también puede representar patrones secuenciales como clases, además de clases derivadas de los metadatos. Existe una gran comunidad de usuarios y herramientas para que las clases se puedan visualizar, editar y clasificar automáticamente en una ontología.
El proyecto “Análisis Computacional de la Música Folclórica Vasca” ha recibido financiación inicial para el primer año de la Diputación Foral de Gipuzkoa. Las fases iniciales son los siguientes:
Después de las fases iniciales, planteamos continuar con codificación de patrones en OWL/DL, considerar nuevos escenarios de data mining con el uso del ontologías y avanzar los métodos de data mining para clasificar aquellas canciones no etiquetadas. El proyecto, en su conjunto, aborda un importante paso hacia el análisis computacional de los cancioneros vascos.
Referencias:
1 Petra Kralj Novak, Nada Lavrac, Geoffrey I. Webb
Supervised descriptive rule discovery: A unifying survey of contrast set, emerging pattern and subgroup mining.
Journal of Machine Learning Research, 10:377-403, 2009.
2 D. Conklin. Discovery of distinctive patterns in music.
Intelligent Data Analysis, 14(5), 547-554, 2010.
3 D. Conklin and C. Anagnostopoulou.
Comparative pattern analysis of Cretan folk songs.
Journal of New Music Research, 40(2):119-125, 2011.
4 R. Hillewaere, B. Manderick, and D. Conklin.
Global feature versus event models for folk song classification.
ISMIR 2009: 10th International Society for Music Information Retrieval Conference,
Kobe, Japan, 729-733, 2009.
La opinión de los lectores:
comments powered by Disqus
