
Si le ha parecido interesante el artículo puede ayudar a difundirlo
 Artetsu Saria 2005
Artetsu Saria 2005
Arbaso Elkarteak Eusko Ikaskuntzari 2005eko Artetsu sarietako bat eman dio Euskonewseko Artisautza atalarengatik
 Buber Saria 2003
Buber Saria 2003
On line komunikabide onenari Buber Saria 2003. Euskonews y Media
 Argia Saria 1999
Argia Saria 1999
Astekari elektronikoari Merezimenduzko Saria

Rodrigo AGERRI
Borja ORBEGOZO
Cristina SARASUA
Euskomedia Fundazioa ha participado junto a la Asociación Vicomtech en el proyecto SeCulart, financiado por el Ministerio de Industria, Comercio y Turismo, en el contexto del Plan Avanza, en la línea “Contenidos para el ocio y la cultura. Creación de aplicaciones y contenidos digitales para actividades de ocio y entretenimiento, artísticas y culturales”.
El proyecto Seculart tiene como objetivo principal la introducción de tecnología lingüística [3,5,6] y de la Web semántica [1,2,4] para mejorar el desarrollo e interoperabilidad de fuentes de datos culturales como la Enciclopedia General Ilustrada del País Vasco “Auñamendi”.
Las organizaciones que custodian el Patrimonio Cultural europeo (museos, galerías, archivos audiovisuales, filmotecas, sociedades fotográficas, bibliotecas) disponen de contenido multimedia digital de alta calidad. Estos proveedores de contenidos, especialmente aquellos de tamaño pequeño-medio, suelen generar contenidos digitales debido a sus propias actividades como la gestión de las colecciones, las exposiciones o la conservación y restauración de sus objetos. Este contenido puede explotarse en un gran número de sectores como la educación (e-learning, educación a distancia, creación de material didáctico), editoriales (libros, vídeos, periódicos, revistas, televisión, publicidad, diseño gráfico), e-comercio (tiendas en las propias organizaciones, tiendas on-line, B2B y B2C) y turismo (material de promoción, terminales en las organizaciones culturales, servicios de valor añadido). Sin embargo, este contenido no se encuentra en la forma adecuada para su acceso externo y suele permanecer “oculto” en los sistemas internos de las instituciones.
Uno de los mayores retos para la incorporación de las Tecnologías de la Información y Comunicaciones en el área del Patrimonio Cultural está relacionado con los sistemas de introducción de información y la estructuración de los datos. Generalmente, el proceso de introducción de la información representa un trabajo importante en el proceso de gestión de la información patrimonial.
Otro segundo reto se centra en proporcionar acceso de un modo tal que se permita que el usuario pueda navegar por todo el contenido disponible. Muchos de los sistemas de bibliotecas digitales tienen una única entidad, texto digital, como el centro de todas las interacciones de los usuarios con el sistema. Esta aproximación no permite obtener toda la diversidad de información almacenada en una biblioteca digital multimedia. Por ejemplo, una institución cultural dispone de datos sobre las piezas de arte, sus creadores y representaciones digitales del objeto, así como la localización y datos temporales.
Finalmente, la información sobre las colecciones de las instituciones culturales es muchas veces incompleta. Las tecnologías de la Web Semántica son una manera de encontrar información adicional en la Web. Esta información adicional puede incluir datos suplementarios de interés para los usuarios finales como biografías de los autores. El hecho de aumentar las colecciones no está limitado a añadir información de fuentes externas. El contenido existente puede ser analizado para generar nuevas relaciones entre los conceptos.
SeCulart trata de mejorar el acceso y la explotación del contenido cultural. Para ello, SeCulart se ha enfocado en el desarrollo de herramientas para facilitar la extracción y clasificación de información y la interoperabilidad semántica de los sistemas de las instituciones culturales de manera que permitan el acceso global a fuentes culturales en entornos heterogéneos y distribuidos.
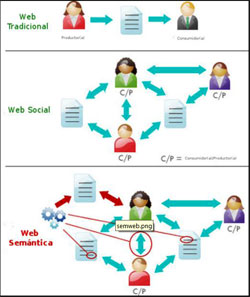
Foto: Asociación Vicomtech.
La producción y creación de datos en la Web ha evolucionado desde sus orígenes hasta el momento actual. El primer gran cambio en la Web fue la diversificación de la producción de información. Desde una separación clara entre creación y producción se ha pasado al momento actual en el que los consumidores de información también se han convertido en productores. Ejemplos paradigmáticos son las redes sociales, blogs, wikis, etc. Si la Web social (también denominada Web 2.0) supuso un cambio con respecto a los medios de producción de datos, la Web semántica tiene el objetivo de enriquecer las relaciones entre los contenidos para ofrecer mejores búsquedas e interoperabilidad entre las diferentes fuentes de datos.
La tecnología de la Web tradicional no permite expresar relaciones entre varios ítems de información en virtud de su contenido o significado, ni el hecho de que puedan pertenecer a categorías diferentes. La tecnología basada en la Web Semántica busca complementar los datos actuales de la Web con descripciones referentes a su contenido o significado que permitan establecer clasificaciones y relaciones a un nivel de abstracción superior. Como beneficio clave de esta nueva clasificación, es posible integrar nuevas fuentes de datos bajo la misma jerarquía de relaciones ya establecidas, lo cual redunda en una mejor interoperabilidad, claridad y reusabilidad de la información. Para aplicar estas tecnologías a la enciclopedia “Auñamendi”, SeCulart utiliza la ontología estándar propuesta en el modelo CIDOC CRM, que define los conceptos y términos específicos del área del Patrimonio Cultural.
La explosión de la Web como medio intercambio de información ha puesto de manifiesto la necesidad de disponer de herramientas que permitan tratar el exceso de información que es necesario manejar a diario. Por ello, no es la cantidad de información lo que transmite conocimiento, sino su acceso en el momento adecuado y en la forma apropiada. Los sistemas de Extracción de la Información analizan texto no estructurado y extraen información que es estructurada bajo un conjunto de categorías y relaciones determinadas previamente. Para ello, es necesaria la automatización de ciertos análisis lingüísticos como la segmentación de palabras, la categorización morfosintáctica, la identificación de Nombres Propios (Entidades Nombradas), el tratamiento de la sinonimia, etc.
SeCulart aplica técnicas de Procesamiento del Lenguaje Natural (PLN) para la extracción de información automática de documentos. El objetivo poner a disposición de los documentalistas de Euskomedia una herramienta que semiautomáticamente extraiga y clasifique información contenida en documentos según la taxonomía establecida en la enciclopedia Auñamendi. Por ejemplo, la identificación de la Voz, de los Topónimos (distinguiendo entre nombres de zona, de provincia, de ciudad, etc.) y las Materias en las que se puede clasificar el documento. Conviene resaltar que el estado del arte actual en Extracción de la Información o Reconocimiento de Entidades Nombradas oscila entre el 60% y el 80% de corrección, y que como tal este tipo de herramientas son concebidas como una asistencia en la labor de documentación y no una sustitución de la labor del documentalista.
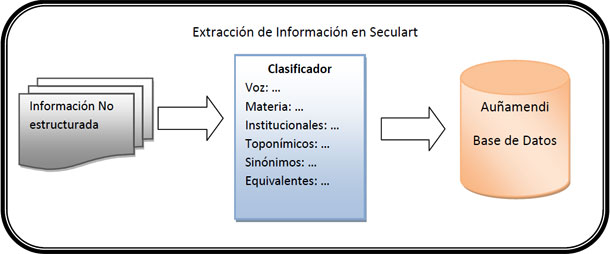
Foto: Asociación Vicomtech.
El proyecto SeCulart ha puesto de manifiesto que el potencial de explotación del contenido digital relacionado con el Patrimonio Cultural puede amplificarse si se agrega y se hace accesible a nivel europeo. Por ejemplo, se podría pensar en una forma unificada de acceso a todas las representaciones digitales, información en forma de texto y material audiovisual relacionado con los trabajos de Rembrandt. Esta información está distribuida en la actualidad entre una serie de museos, galerías, filmotecas y bibliotecas en el mundo, con una gran parte de información que no se encuentra ni disponible on-line. Esta forma de acceso unitaria permitirá al usuario acceder a dichos contenidos como si formaran una única colección, proporcionando un valor añadido para dicho usuario cuando desee conocer aspectos de la vida y obra del una personalidad, institución o lugar.
Referencias
1. Dean Allemang and James Hendler (2008). Semantic Web for the Working Ontologist: Effective Modeling in RDFS and OWL. Morgan Kaufmann.
2. Tim Berners-Lee, James Hendler and Ora Lassila (2001). The Semantic Web. Scientific American Magazine.
3. Paul Buitelaar, Philipp Cimiano, Anette Frank, Matthias Hartung, and Stefania Racioppa. (2008). Ontology-based Information Extraction and Integration from Heterogeneous Data Sources. In: International Journal of Human-Computer Studies, 66.
4. John Davies (2006). Semantic Web Technologies: Trends and Research in Ontology-based Systems. Wiley. ISBN 0470025964.
5. Andrew McCallum. (2005). Information Extraction: Distilling Structured Data from Unstructured Text. In: ACM Queue, 3(9)
6. Sunita Sarawagi. (2008). Information extraction. FnT Databases, 1(3), 2008.
Rodrigo Agerri, Borja Orbegozo, Cristina Sarasua: Vicomtech
La opinión de los lectores:
comments powered by Disqus
